Trip.com: Large Scale Cloud Native Networking & Security with Cilium/eBPF (eBPFSummit, 2022)
This is an entended version of our talk at eBPF Summit 2022: Large scale cloud native networking and security with Cilium/eBPF: 4 years production experiences from Trip.com. This version covers more contents and details that’s missing from the talk (for time limitation).

- Abstract
- 1 Cloud Infrastructure at Trip.com
- 2 Cilium at Trip.com
- 3 Advanced trouble shooting skills
- 4 Summary
- References
Abstract
In Trip.com, we rolled out our first Cilium node (bare metal) into production in 2019. Since then, almost all our Kubernetes clusters - both on-premises baremetal and self-managed clusters in public clouds - have switched to Cilium.
With ~10K nodes, ~300K pods running on Kubernetes now, Cilium powers our business critical services such as hotel search engines, financial/payment services, in-memory databases, data store services, with a wide range of requirements in terms of latency, throughput, etc.
From our 4 years of experiences, the audience will learn cloud native networking and security with Cilium including:
- How to use CiliumNetworkPolicy for L3/L4 access control including extending the security model to BM/VM instances;
- Our new multi-cluster solution called KVStoreMesh as an alternative ClusterMesh and how we made it compatible with the community for easy upgrade;
- Building stability at scale, like managing control plane and multi-cluster outages, and the improvements we made to Cilium as a result.
1 Cloud Infrastructure at Trip.com
1.1 Layered architecture
The Trip.com cloud team is responsible for our infrastructure over the globe, as shown below:
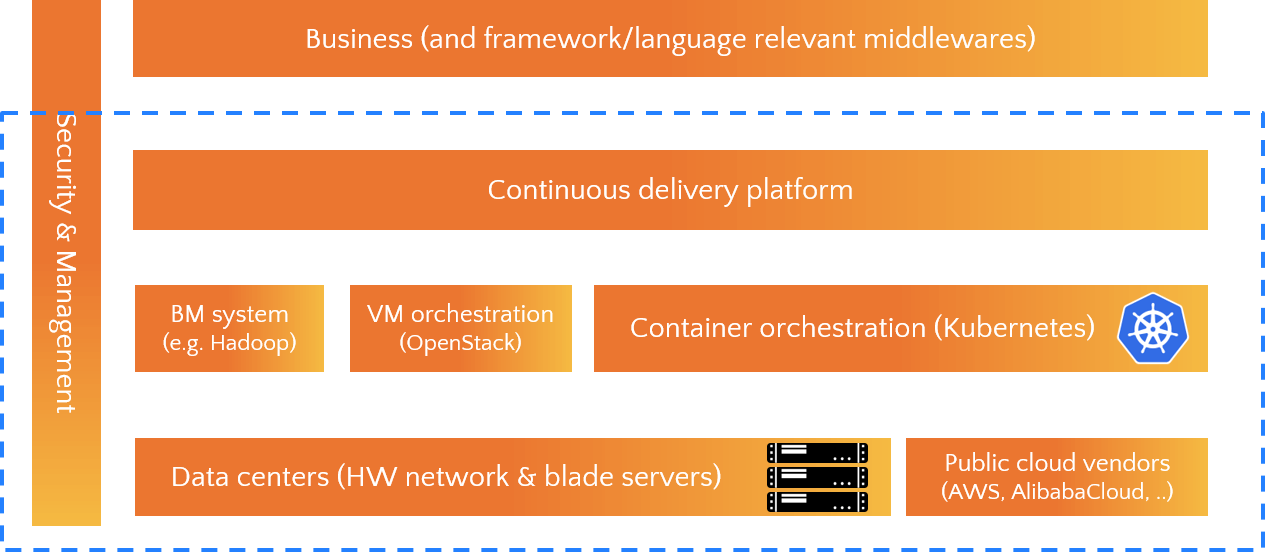
- In the bottom we have data centers and several public cloud vendors;
- Above the bottom is our orchestration systems for BM, VM and container;
- One layer up is the internally developed continues delivery platform (CI/CD);
- At the top are our business services and corresponding middlewares;
- In the vertical direction, we have security & management tools at different levels.
The cloud scope is the box shown in the picture.
1.2 More details
More specific information about our infra:

- Most of our workloads now run on Kubernetes, we have 3 big
clusters and several small ones, with total
~10knodes and~300kpods; - Most Kubernetes nodes are blade servers; which
- Run with internally maintained
4.19/5.10kernels; - And for inter-host networking, we use BGP for on-premises clusters and ENI for self-managed clusters on the cloud.
2 Cilium at Trip.com
2.1 Timeline of rolling out
This is a simple timeline of our rolling out process:
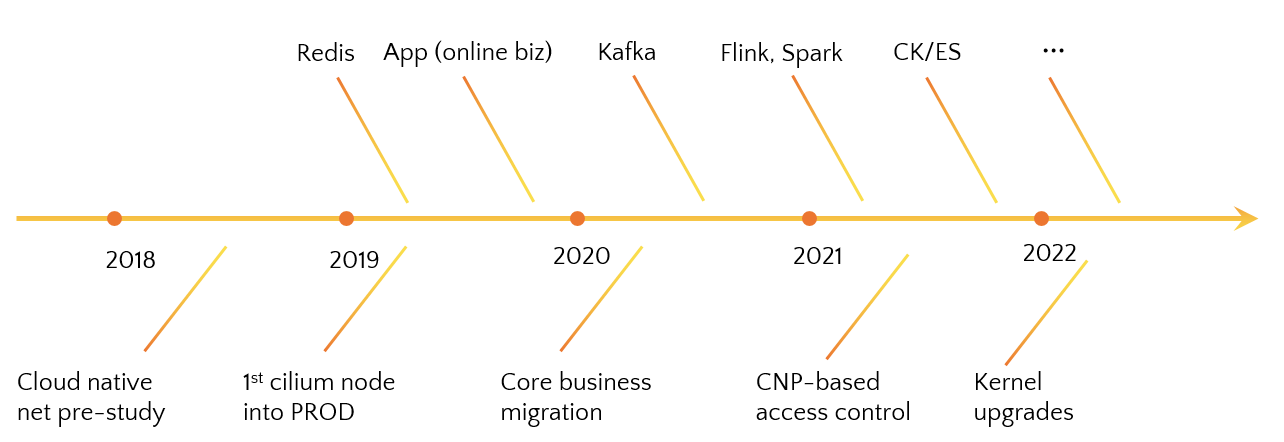
- We started investigating cloud-native networking solution in 2018 [9], and of course, Cilium won out;
- Our first cilium node rolled into production in 2019 [10];
- Since then, all kinds of our business and infrastructure services began to migrate to Cilium, transparently.
In 2021, with most online businesses already in Cilium, we started a security project based on Cilium network policy [8].
Functionalities we’re using:
- Service LoadBalancing (eBPF/XDP)
- CiliumNetworkPolicy (CNP)
- eBPF host routing
- eBPF bandwidth manager
- Hubble (part of)
- Rsyslog driver
- Performance boost options like sockops, eBPF redirects
- …
2.2 Customizations
First, two Kubernetes clusters shown here,
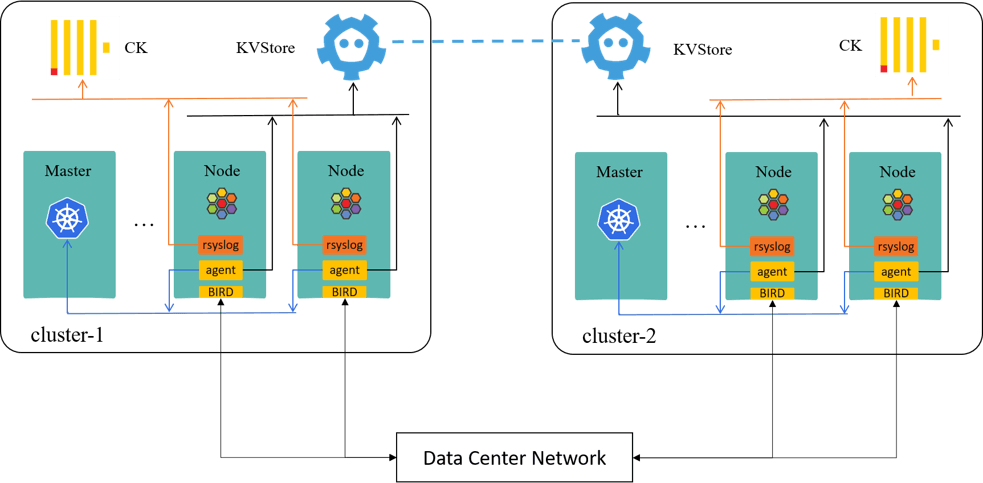
Some of our customizations based on the above topology:
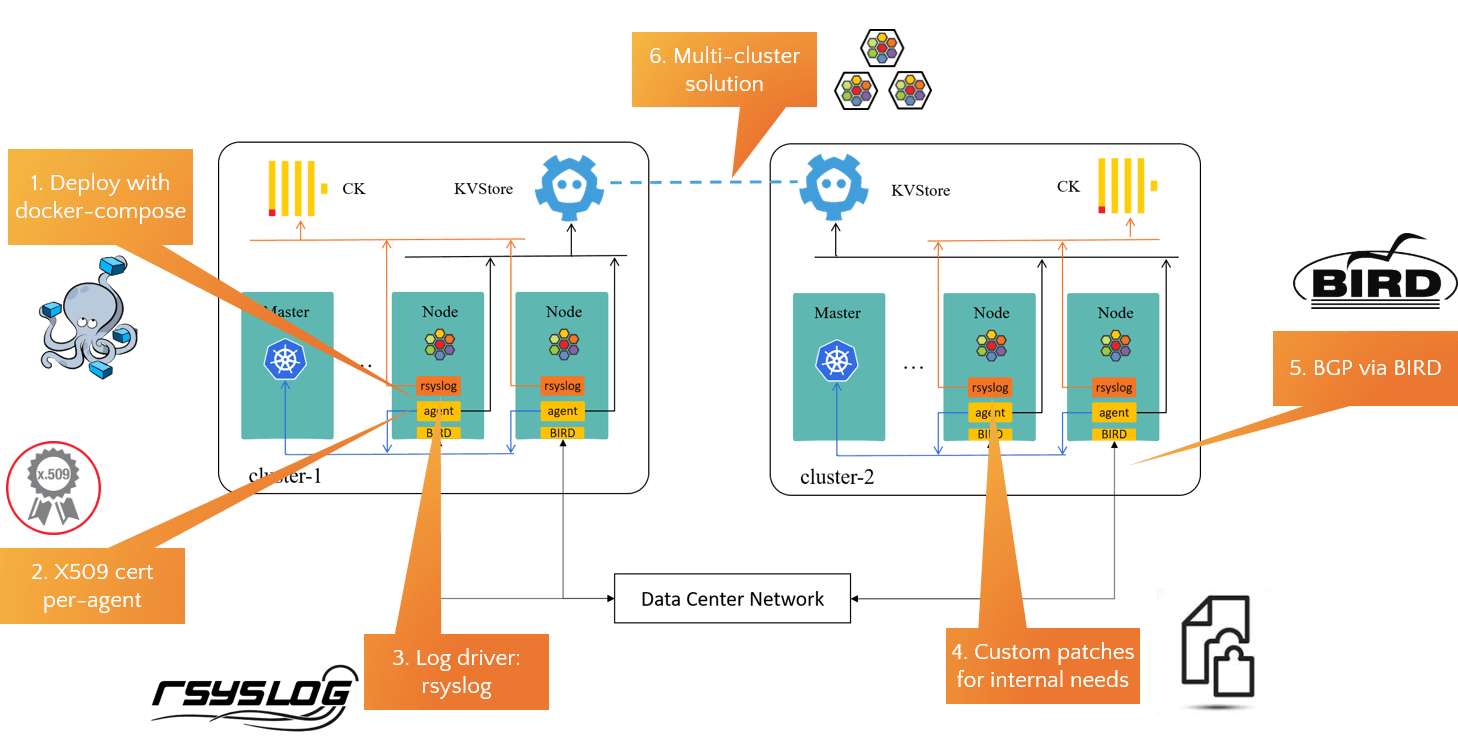
- Use docker-compose to deploy cilium to remove kubernetes dependency [1];
- Assign each agent a dedicated certificate for Kubernetes authentication, instead of the shared seviceaccount by all agents;
- We’ve helped to maturate Cilium’s rsyslog driver, and have sent all agent logs to ClickHouse for trouble shooting;
- Few patches added to facilitate business migration, but this is not that general, so we didn’t upstream them;
- Use BIRD as BGP agent instead of the suggested kube-router then, and we’ve contributed a BGP+Cilium guide to Cilium documentation;
- We developed a new multi-cluster solution called KVStoreMesh [4]. More on this lader.
2.3 Optimizations & tunings
Now the optimization and tuning parts.


2.3.1 Decouple installation
As mentioned just now, the first thing we’ve done is decoupling Cilium deploying/installation from Kubernetes: no daemonset, no configmap. All the configurations needed by the agent are on the node.
This makes agents suffer less from Kubernetes outages, but more importantly, each agent is now completely independent in terms of configuration and upgrade.
2.3.2 Avoid retry/restart storms
The second consideration is to avoid retry storms and burst starting, as requests will surge by two orders of magnitude or even higher when outage occurs, which could easily crash or stuck central components like Kubernetes and kvstore.
We use an internally developed restart backoff (jitter+backoff) mechanism to avoid such cases. the jitter window is calculated according to cluster scale. Such as,
- For a cluster with 1000 nodes, the jitter window may be 20 minutes, during which period each agent is allowed to start one and only one time, then backed off.
- For a cluster with 5000 nodes, the jitter window may be 60 minutes.
- The backoff mechanism is implemented as a bash script, used in docker-compose as a “pre-start hook”, Cilium code suffers no changes.
Besides, we’ve assigned each agent a distinct certificate (each agent has a dedicated username but belongs to a common user group), which enables Kubernetes to perform rate limiting on Cilium agents with APF (API Priority and Fairness). No Cilium code changes to achieve this, too.
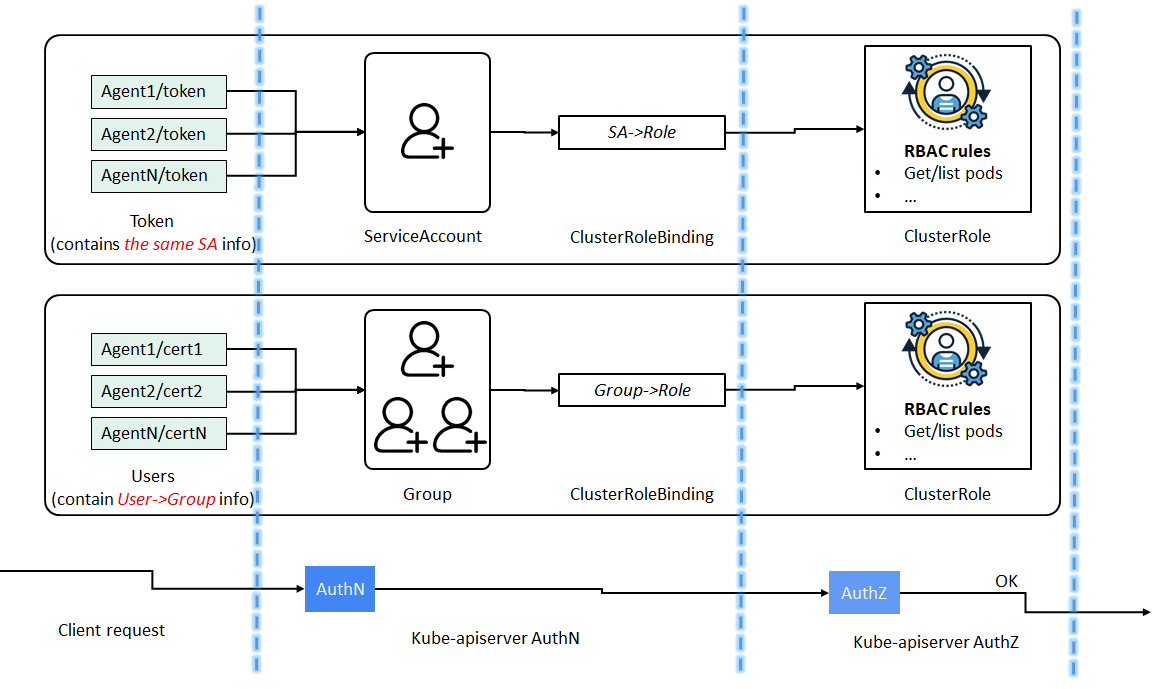
Refer to our previous blogs if you’d like to learn more about Kubernetes AuthN/AuthZ models [2,3].
2.3.3 Stability first
Trip.com provides online booking services worldwide with 7x24h, so at any time of any day, business service down would lead to instantaneous losses to the company. So, we can’t risk letting foundational services like networking to restart itself by the simple “fast failure” rule, but favor necessary human interventions and decisions.
When failure arises, we’d like services such as Cilium to be more patient, just wait there and keep the current business uninterrupted, letting system developers and maintainers decide what to do; fast failure and automatic retries make things worse more than often in such cases.
Some specific options (with exemplanary configurations) to tune this behavior:
--allocator-list-timeout=3h--kvstore-lease-ttl=86400s--k8s-syn-timeout=600s--k8s-heartbeat-timeout=60s
Refer to the Cilium documentation or source code to figure out what each option exactly means, and customize them according to your needs.
2.3.4 Planning for scale
Depending on your cluster scale, certain stuffs needs to be planned in advance.
For example, identity relevant labels (--labels) directly determine
the maximum pods in your cluster: a group of labels map to
one identity in Cilium, so in it’s design, all pods with the same labels share the same identity.
But, if your --labels=<labels> is too fine grained (which is unfortunately the default
case), it may result in each pod has a distinct identity in the worse case, then your cluster scale is
upper limited to 64K pods, as identity is represented with a 16bit integer. Refer to [8] for more information.
Besides, there are parameters that needs to be decided or tuned according to your workload throughput, such as identity allocation mode, connection tracking table.
Options:
--cluster-id/--cluster-name: avoid identity conflicts in multi-cluster scenarios;-
--labels=<labellist>identity relavent labelsWe use
kvstoremode, and running kvstore (cilium etcd) on dedicated blade servers for large clusters. --identity-allocation-modeand kvstore benchmarking if kvstore mode is used--bpf-ct-*--api-rate-limit- Monitor aggregation options for reducing volume of observability data
2.3.5 Performance tuning
Cilium includes many high performans options such as sockops and BPF host routing, and of course, all those features needs specific kernel versions support.
--socops-enable--bpf-lb-sock-hostns-only- …
Besides, disable some debug level options are also necessary:
--disable-cnp-status-updates- …
2.3.6 Observability & alerting
The last aspect we’d like to talk about is observability.
- Metric
- Logging
- Tracing
Apart from the metrics data from Cilium agent/operator, we also collected all agent/operator logs (logging data) and sent to ClickHouse for analyzing, so, we could alert on abnormal metrics as well as error/warning logs,
Besides, tracing can be helpful too, more on this lader.
2.3.7 Misc options
--enable-hubble--keep-config--log-drivers--policy-audit-mode
2.4 Multi-cluster solution
Now let’s have a look at the multi-cluster problem.
For historical reasons, our businesses are deployed across different data centers and Kubernetes clusters. So there are inter-cluster communications without L4/L7 border gateways. This is a problem for access control, as Cilium identity is a cluster scope object.
2.4.1 ClusterMesh
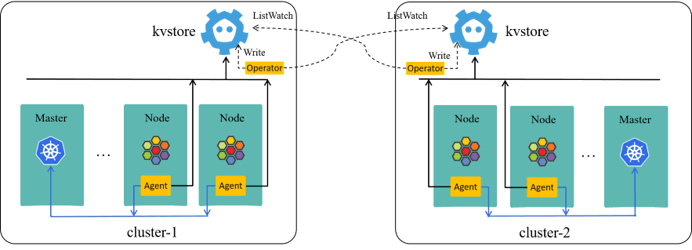
The community solution to this problem is ClusterMesh as shown here,
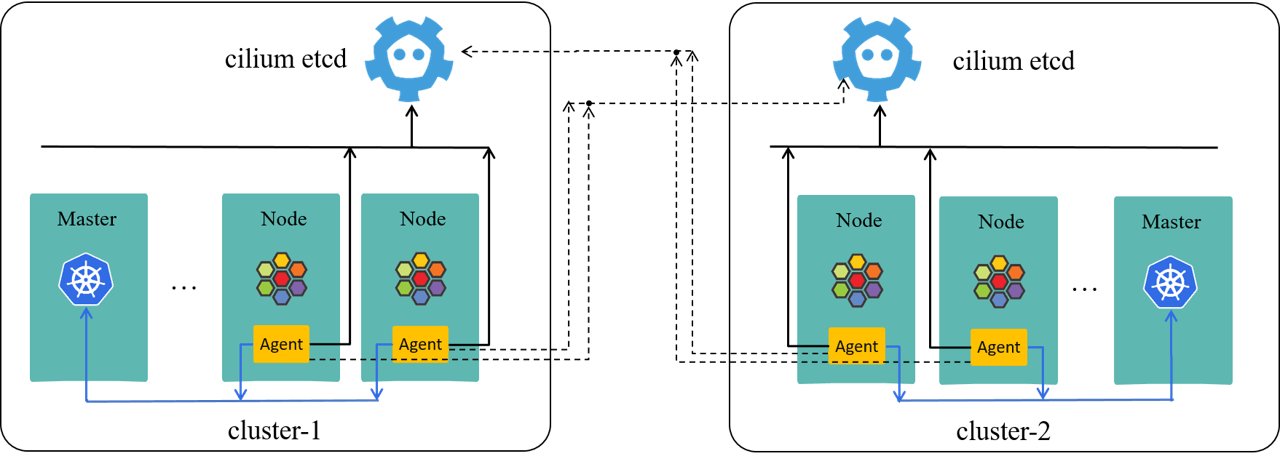
ClusterMesh requires each agent to connect to each kvstore in all clusters, effectively resulting in a peer-to-peer mesh. While this solution is straight forward, it suffers stability and scalability issues, especially for large clusters.
In short, when a single cluster down, the failure would soon propagate to all the other clusters in-the-mesh, And eventually all the clusters may crash at the same time, as illustrated below:
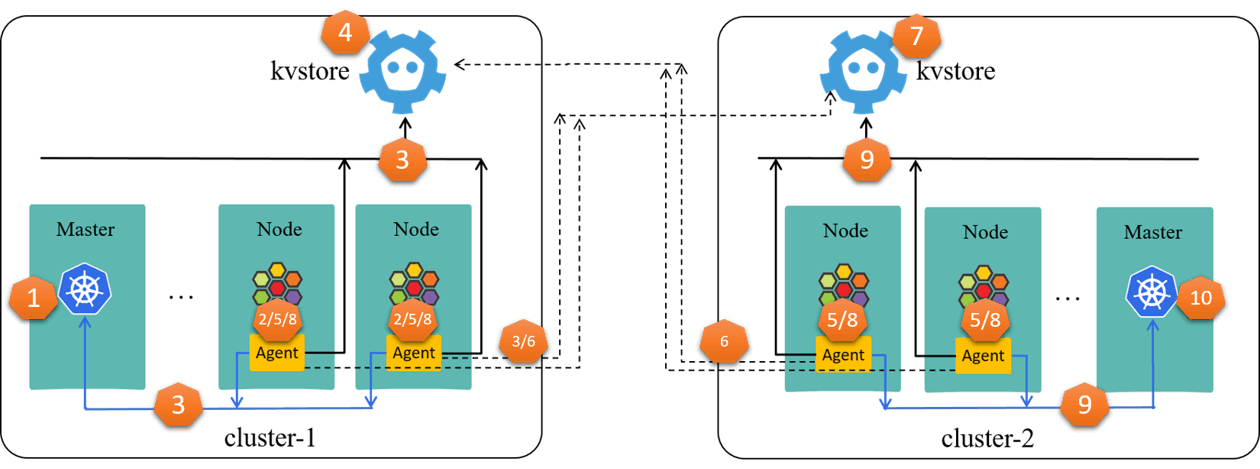
Essentially, this is because clusters in ClusterMesh are too tightly coupled.
2.4.2 KVStoreMesh
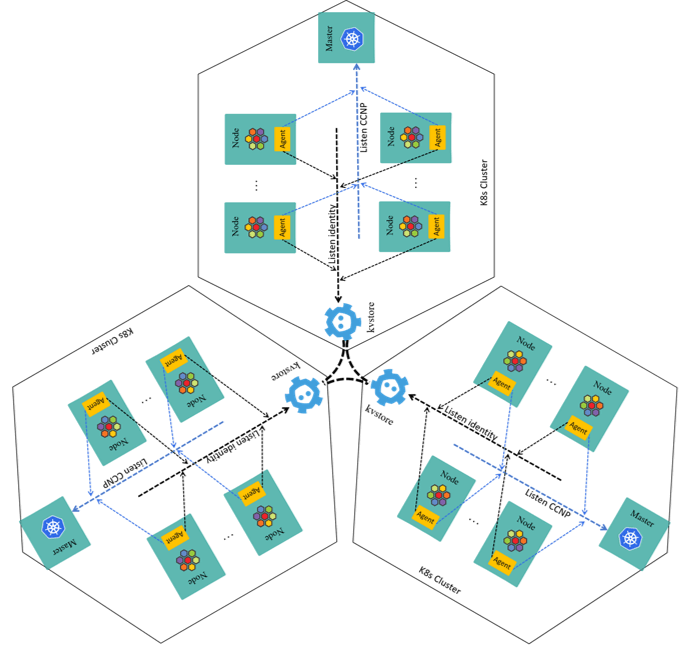
Our solution to this problem is very simple in concept: pull metadata from all the remote kvstores, and push to local one after filtering.
The three-cluster case show this concept more clearly: only kvstores are involved,
In ClusterMesh, agents get remote metadata from remote kvstores; in KVStoreMesh, they get from the local one.
Thanks to cilium’s good design, this only needs a few improvements and/or bugfixes to the agent and operator [4], and we’ve already upstreamed some of them. A kvstoremesh-operator is newly introduced, and maintained internally currently; we’ll devote more efforts to upstream it in the next, too.
Besides, we’ve also developed a simple solution to let Cilium be-aware of our legacy workloads like virtual machines in OpenStack, the-solultion is called CiliumExeternalResource. Please see our previous blog [8] if you’re interested in.
3 Advanced trouble shooting skills
Now let’s back to some handy stuffs.
The fist one, debugging.
3.1 Debugging with delve/dlv
Delve is a good friend, and our docker-compose way makes debugging more easier, as each agent independently deployed, commands can be executed on the node to start/stop/reconfigure the agent.
# Start cilium-agent agent container with entrypoint `sleep 10d`, then enter the container
(node) $ docker exec -it cilium-agent bash
(cilium-agent ctn) $ dlv exec /usr/bin/cilium-agent -- --config-dir=/tmp/cilium/config-map
Type 'help' for list of commands.
(dlv)
(dlv) break github.com/cilium/cilium/pkg/endpoint.(*Endpoint).regenerateBPF
Breakpoint 3 set at 0x1e84a3b for github.com/cilium/cilium/pkg/endpoint.(*Endpoint).regenerateBPF() /go/src/github.com/cilium/cilium/pkg/endpoint/bpf.go:591
(dlv) break github.com/cilium/cilium/pkg/endpoint/bpf.go:1387
Breakpoint 4 set at 0x1e8c27b for github.com/cilium/cilium/pkg/endpoint.(*Endpoint).syncPolicyMapWithDump() /go/src/github.com/cilium/cilium/pkg/endpoint/bpf.go:1387
(dlv) continue
...
(dlv) clear 1
Breakpoint 1 cleared at 0x1e84a3b for github.com/cilium/cilium/pkg/endpoint.(*Endpoint).regenerateBPF() /go/src/github.com/cilium/cilium/pkg/endpoint/bpf.go:591
(dlv) clear 2
Breakpoint 2 cleared at 0x1e8c27b for github.com/cilium/cilium/pkg/endpoint.(*Endpoint).syncPolicyMapWithDump() /go/src/github.com/cilium/cilium/pkg/endpoint/bpf.go:1387
We’ve tracked down several bugs in this way.
3.2 Tracing with bpftrace
Another useful tool is bpftrace for live tracing.
But note that there are some differences for tracing a process in container. You need to find the PID namespace or absolute path of the cilium-agent binary on the node.
3.2.1 With absolute path
# Check cilium-agent container
$ docker ps | grep cilium-agent
0eb2e76384b3 cilium:20220516 "/usr/bin/cilium-agent ..." 4 hours ago Up 4 hours cilium-agent
# Find the merged path for cilium-agent container
$ docker inspect --format "{{.GraphDriver.Data.MergedDir}}" 0eb2e76384b3
/var/lib/docker/overlay2/0a26c6/merged # 0a26c6.. is shortened for better viewing
# The object file we are going to trace
$ ls -ahl /var/lib/docker/overlay2/0a26c6/merged/usr/bin/cilium-agent
/var/lib/docker/overlay2/0a26c6/merged/usr/bin/cilium-agent # absolute path
# Or you can find it bruteforcelly if there are no performance (e.g. IO spikes) concerns:
$ find /var/lib/docker/overlay2/ -name cilium-agent
/var/lib/docker/overlay2/0a26c6/merged/usr/bin/cilium-agent # absolute path
Anyway, after located the target file and checked out the symbols in it,
$ nm /var/lib/docker/overlay2/0a26c6/merged/usr/bin/cilium-agent
0000000001d3e940 T type..hash.github.com/cilium/cilium/pkg/k8s.ServiceID
0000000001f32300 T type..hash.github.com/cilium/cilium/pkg/node/types.Identity
0000000001d05620 T type..hash.github.com/cilium/cilium/pkg/policy/api.FQDNSelector
0000000001d05e80 T type..hash.github.com/cilium/cilium/pkg/policy.PortProto
...
you can initiate userspace probes like below, printing things you’d like to see:
$ bpftrace -e \
'uprobe:/var/lib/docker/overlay2/0a26c6/merged/usr/bin/cilium-agent:"github.com/cilium/cilium/pkg/endpoint.(*Endpoint).regenerateBPF" {printf("%s\n", ustack);}'
Attaching 1 probe...
github.com/cilium/cilium/pkg/endpoint.(*Endpoint).regenerateBPF+0
github.com/cilium/cilium/pkg/endpoint.(*EndpointRegenerationEvent).Handle+1180
github.com/cilium/cilium/pkg/eventqueue.(*EventQueue).run.func1+363
sync.(*Once).doSlow+236
github.com/cilium/cilium/pkg/eventqueue.(*EventQueue).run+101
runtime.goexit+1
2.3.2 With PID /proc/<PID>
A more convenient and conciser way is to find the PID namespace and passing it to
bpftrace, this will make the commands much shorter:
$ sudo docker inspect -f '{{.State.Pid}}' cilium-agent
109997
$ bpftrace -e 'uprobe:/proc/109997/root/usr/bin/cilium-agent:"github.com/cilium/cilium/pkg/endpoint.(*Endpoint).regenerate" {printf("%s\n", ustack); }'
Or,
$ bpftrace -p 109997 -e 'uprobe:/usr/bin/cilium-agent:"github.com/cilium/cilium/pkg/endpoint.(*Endpoint).regenerate" {printf("%s\n", ustack); }'
3.3 Manipulate BPF map with bpftool
Now consider a specific question: how could you determine if a CNP actually takes effect? There are several ways:
$ kubectl get cnp -n <ns> <cnp> -o yaml # spec & status in k8s
$ cilium endpoint get <ep id> # spec & status in cilium userspace
$ cilium bpf policy get <ep id> # summary of kernel bpf policy status
- Query Kubernetes? NO, that’s too high-level;
- Check out endpoint status? NO, it’s a userspace state and still too high-level;
- Check bpf policy with cilium command? Well, it’s indeed a summary of the BPF policies in use, but the summary code itself may also have bugs;
The most underlying policy state is the BPF policy map in kernel, we can view it with bpftool:
$ bpftool map dump pinned cilium_policy_00794 # REAL & ULTIMATE policies in the kernel!
But to use this tool you need to first get yourself familiar with some Cilium data structures. Such as, how an IP address corresponds to an identity, and how to combine Identity, port, protol, traffic direction to form a key in BPF policy map.
# Get the corresponding identity of an (client) IP address
$ cilium bpf ipcache get 10.2.6.113
10.2.6.113 maps to identity 298951 0 0.0.0.0
# Convert a numeric identity to its hex representation
$ printf '%08x' 298951
00048fc7
# Search if there exists any policy related to this identity
#
# Key format: identity(4B) + port(2B) + proto(1B) + direction(1B)
# For endpoint 794's TCP/80 ingress, check if allow traffic from identity 298951
$ bpftool map dump pinned cilium_policy_00794 | grep "c7 8f 04 00" -B 1 -A 3
key:
c7 8f 04 00 00 50 06 00 # 4B identity + 2B port(80) + 1B L4Proto(TCP) + direction(ingress)
value:
00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
The key and value data structures:
// PolicyKey represents a key in the BPF policy map for an endpoint. It must
// match the layout of policy_key in bpf/lib/common.h.
// +k8s:deepcopy-gen:interfaces=github.com/cilium/cilium/pkg/bpf.MapKey
type PolicyKey struct {
Identity uint32 `align:"sec_label"`
DestPort uint16 `align:"dport"` // In network byte-order
Nexthdr uint8 `align:"protocol"`
TrafficDirection uint8 `align:"egress"`
}
// PolicyEntry represents an entry in the BPF policy map for an endpoint. It must
// match the layout of policy_entry in bpf/lib/common.h.
// +k8s:deepcopy-gen:interfaces=github.com/cilium/cilium/pkg/bpf.MapValue
type PolicyEntry struct {
ProxyPort uint16 `align:"proxy_port"` // In network byte-order
Flags uint8 `align:"deny"`
Pad0 uint8 `align:"pad0"`
Pad1 uint16 `align:"pad1"`
Pad2 uint16 `align:"pad2"`
Packets uint64 `align:"packets"`
Bytes uint64 `align:"bytes"`
}
// pkg/maps/policymap/policymap.go
// Allow pushes an entry into the PolicyMap to allow traffic in the given
// `trafficDirection` for identity `id` with destination port `dport` over
// protocol `proto`. It is assumed that `dport` and `proxyPort` are in host byte-order.
func (pm *PolicyMap) Allow(id uint32, dport uint16, proto u8proto.U8proto, trafficDirection trafficdirection.TrafficDirection, proxyPort uint16) error {
key := newKey(id, dport, proto, trafficDirection)
pef := NewPolicyEntryFlag(&PolicyEntryFlagParam{})
entry := newEntry(proxyPort, pef)
return pm.Update(&key, &entry)
}
bpftool also comes to rescue in emergency cases, such as when
traffic is denied but your Kubernetes or Cilium agent can’t be ready,
just insert an allow-any rule like this:
# Add an allow-any rule in emergency cases
$ bpftool map update pinned <map> \
key hex 00 00 00 00 00 00 00 00 \
value hex 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 noexist
3.4 Manipulate kvstore contents with etcdctl and API
The last skill we’d like to share is to manipulate kvstore contents.
Again, this needs a deep understanding about the Cilium data models. such as, with the following three entries inserted into kvstore,
$ etcdctl put "cilium/state/identities/v1/id/15614229" \
'k8s:app=app1;k8s:io.cilium.k8s.policy.cluster=cluster1;k8s:io.cilium.k8s.policy.serviceaccount=default;k8s:io.kubernetes.pod.namespace=ns1;'
$ etcdctl put 'k8s:app=app1;k8s:io.cilium.k8s.policy.cluster=cluster1;k8s:io.cilium.k8s.policy.serviceaccount=default;k8s:io.kubernetes.pod.namespace=ns1;/10.3.9.10' \
15614229
$ etcdctl put "cilium/state/ip/v1/cluster1/10.3.192.65" \
'{"IP":"10.3.192.65","Mask":null,"HostIP":"10.3.9.10","ID":15614299,"Key":0,"Metadata":"cilium-global:cluster1:node1:2404","K8sNamespace":"ns1","K8sPodName":"pod1"}'
all the cilium-agents will be notified that there is a pod created in Kubernetes
cluster1, namespace default, with PoIP, NodeIP, NodeName, pod label and
identity information in the entries.
Essentially, this is how we’ve injected our VM, BM and non-cilium-pods into Cilium world in our CER solution (see our previous post [8] for more details); it’s also a foundation of Cilium network policy.
WARNING: manipulation of kvstores as well as BPF maps are dangers, so we do not recommend to perform these operations in production environments, unless you know what you are doing.
4 Summary
We’ve been using Cilium since 1.4 and have upgraded all the way to 1.10 now (1.11 upgrade already planned), it’s supporting our business and infrastructure critical services. With 4 years experiences, we believe it’s not only production ready for large scale, but also one of the best candidates in terms of performance, feature, community and so on.
In the end, I’d like to say special thanks to Andre, Denial, Joe, Martynas, Paul, Quentin, Thomas and all the Cilium guys. The community is very nice and has helped us a lot in the past.
References
- github.com/ctripcloud/cilium-compose
- Cracking Kubernetes Authentication (AuthN) Model
- Cracking Kubernetes RBAC Authorization (AuthZ) Model
- KVStoreMesh proposal
- ClusterMesh: A Hands-on Guide
- Cracking Kubernetes Network Policy
- What’s inside cilium-etcd and what’s not
- Trip.com: First Step towards Cloud Native Security, 2021
- Ctrip Network Architecture Evolution in the Cloud Computing Era, 2019
- Trip.com: First Step towards Cloud Native Networking, 2020